0x00 案例实现
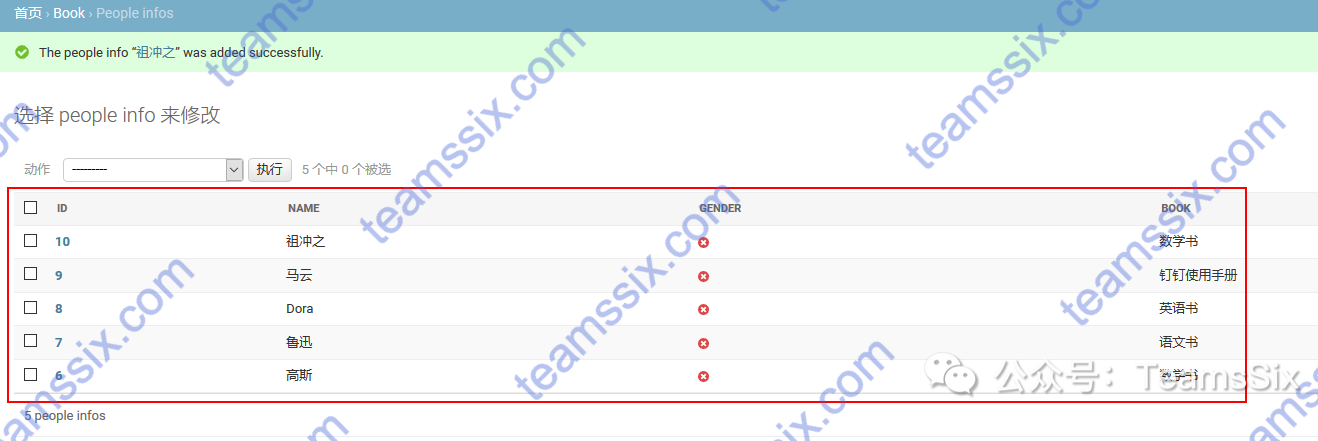
创建的项目名称为BookManager,创建应用名称为Book,完成图书信息的维护
访问图书信息列表127.0.0.1:8000/booklist,并且点击每个图书能够跳转到对应图书人物信息界面
0x01 代码实现
2020-03-04