0x00 前言
前文中讲到了将爬取的数据导出到文件中,接下来就在前文的代码基础之上,将数据导出到 MongoDB中。
0x01 配置 pipelines.py
首先来到 pipelines.py 文件下,在这里写入连接操作数据库的一些功能。
将连接操作 mongo 所需要的包导入进来
import pymongo接下来定义一些参数,注意下面的函数都是在 TeamssixPipeline 类下的
@classmethod
def from_crawler(cls, crawler):
cls.DB_URL = crawler.settings.get('MONGO_DB_URI')
cls.DB_NAME = crawler.settings.get('MONGO_DB_NAME')
return cls()
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.DB_URL)
self.db = self.client[self.DB_NAME]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
collection = self.db[spider.name]
collection.insert_one(dict(item))
return item0x02 配置 settings.py
ITEM_PIPELINES 是settings.py 文件自带的,把注释符号删掉就好
ITEM_PIPELINES = {
'teamssix.pipelines.TeamssixPipeline': 300, #优先级,1-1000,数值越低优先级越高
}
MONGO_DB_URI = 'mongodb://localhost:27017' #mongodb 的连接 url
MONGO_DB_NAME = 'blog' #要连接的库0x02 运行
直接执行命令,不加参数
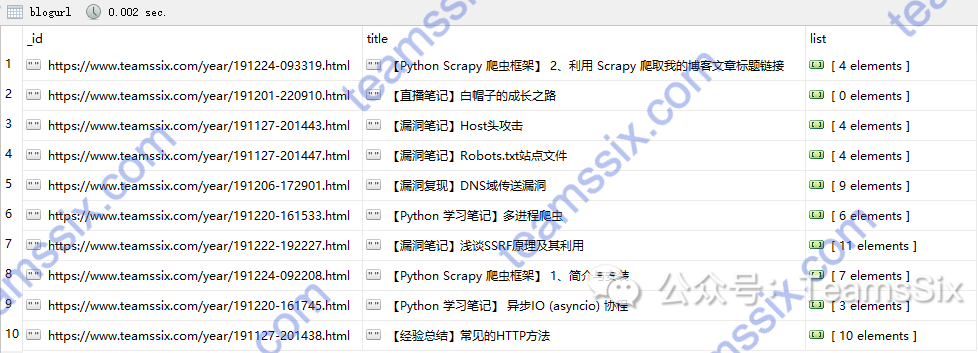
scrapy crawl blogurl注意,如果原来 MongoDB 中没有我们要连接的库, MongoDB 会自己创建,就不需要自己创建了,所以还是蛮方便的,使用 Robo 3T 打开后,就能看到刚才存进的数据。
更多信息欢迎关注我的个人微信公众号:TeamsSix
参考链接:
https://youtu.be/aDwAmj3VWH4
http://doc.scrapy.org/en/latest/topics/architecture.html
https://lemmo.xyz/post/Scrapy-To-MongoDB-By-Pipeline.html
