欢迎关注我的个人微信公众号:TeamsSix
给大佬递茶,求关注 ~
阅读更多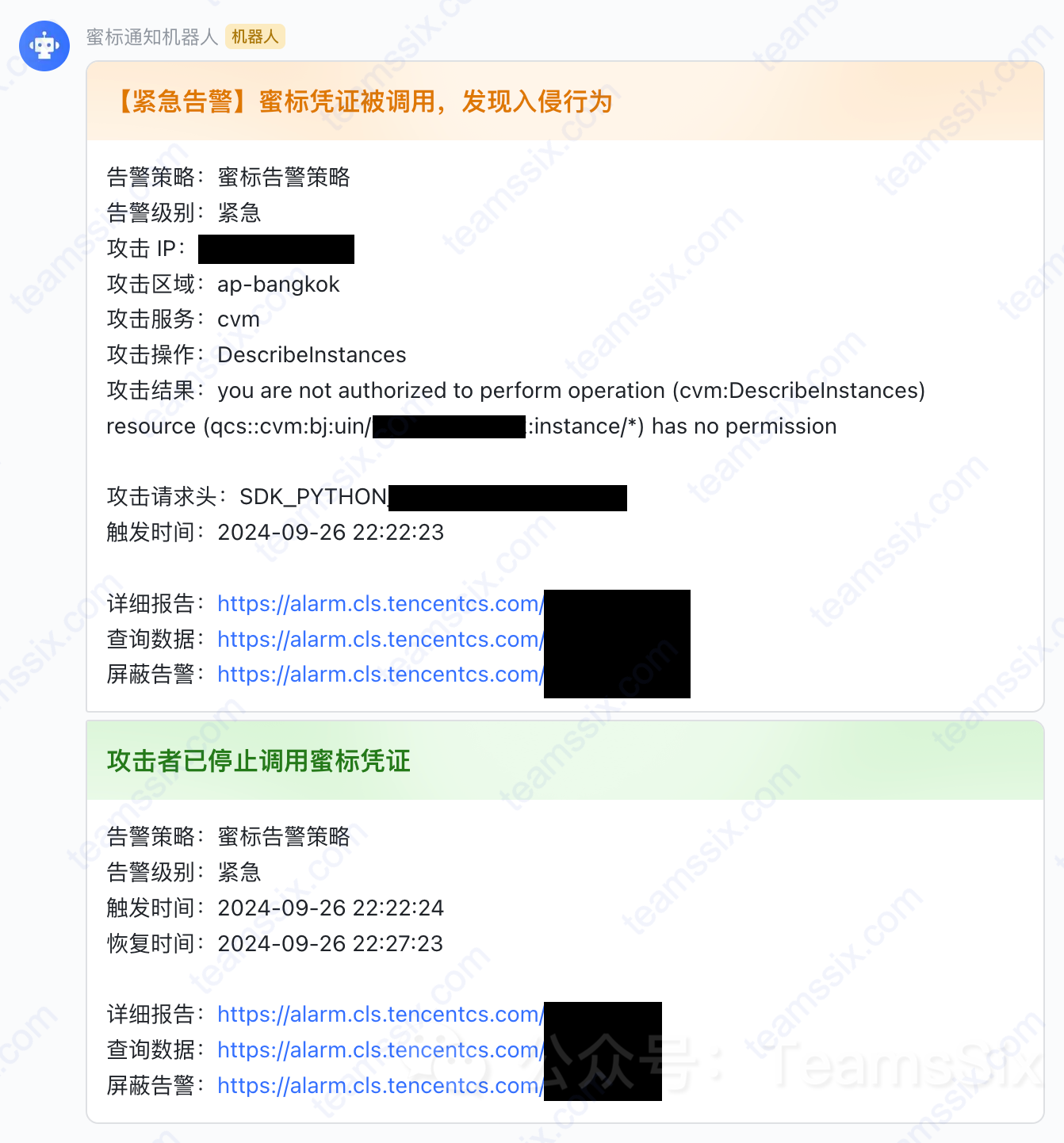 使用云访问凭证蜜标及时发现入侵行为
使用云访问凭证蜜标及时发现入侵行为
 LC 多云资产梳理工具已更新至 v1.1.0 版本
LC 多云资产梳理工具已更新至 v1.1.0 版本
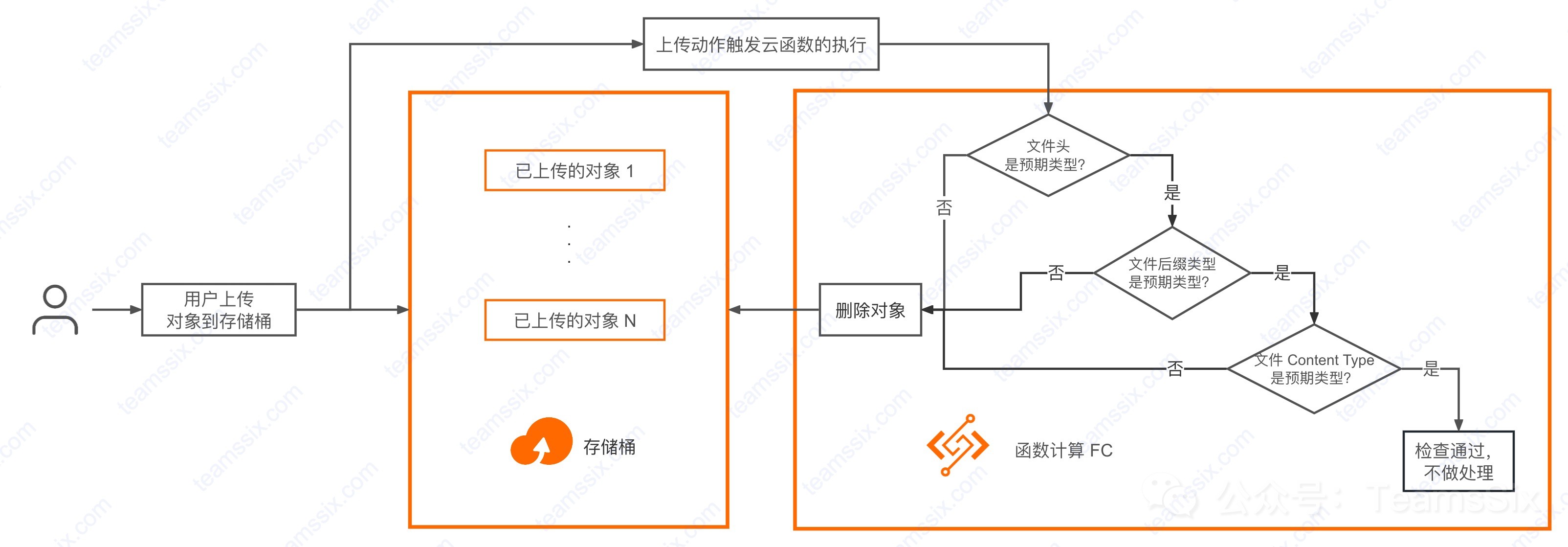 使用云函数限制存储桶上传类型
使用云函数限制存储桶上传类型
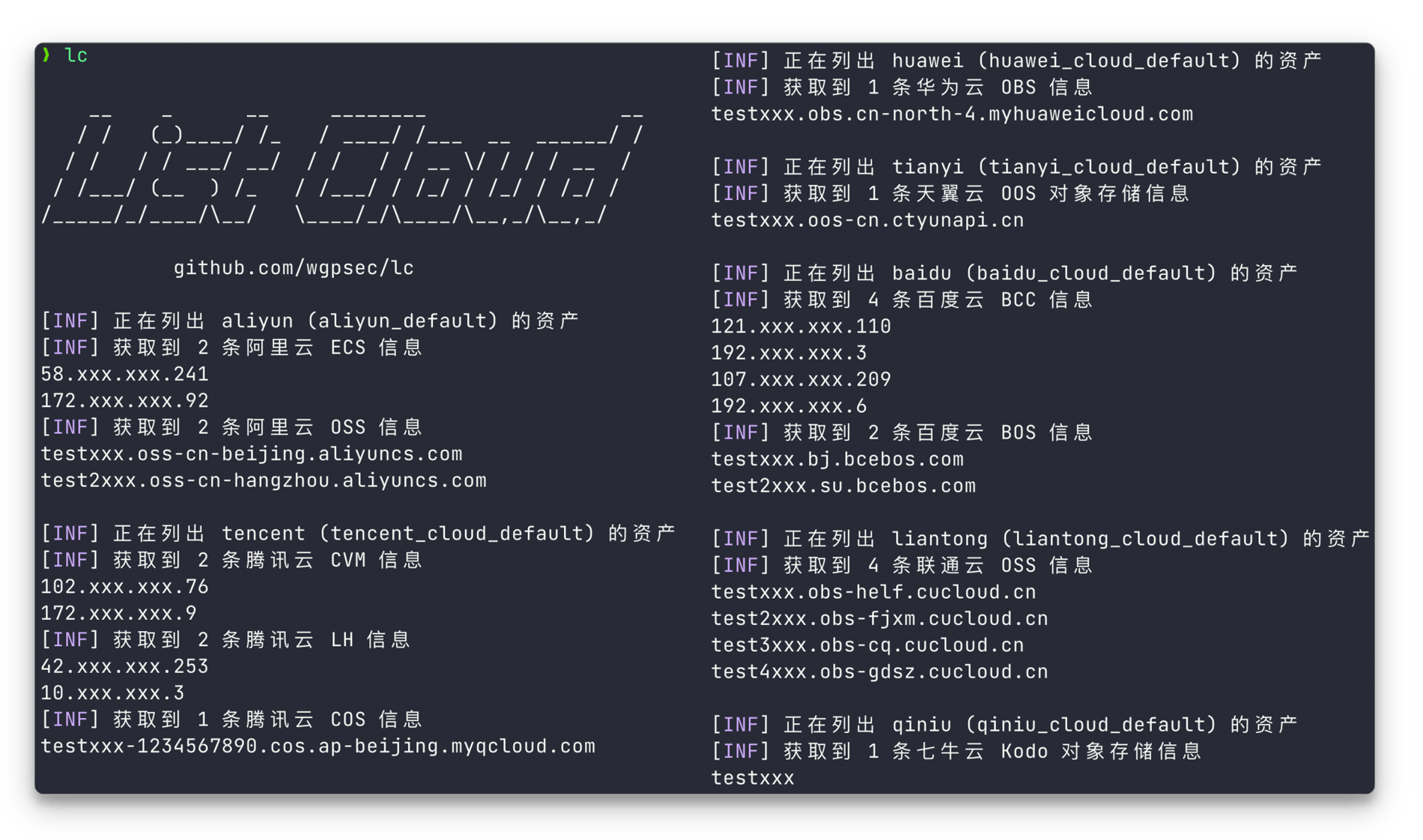 LC 多云攻击面资产梳理开源工具
LC 多云攻击面资产梳理开源工具
 T Wiki 云安全知识库半年更新汇总
T Wiki 云安全知识库半年更新汇总
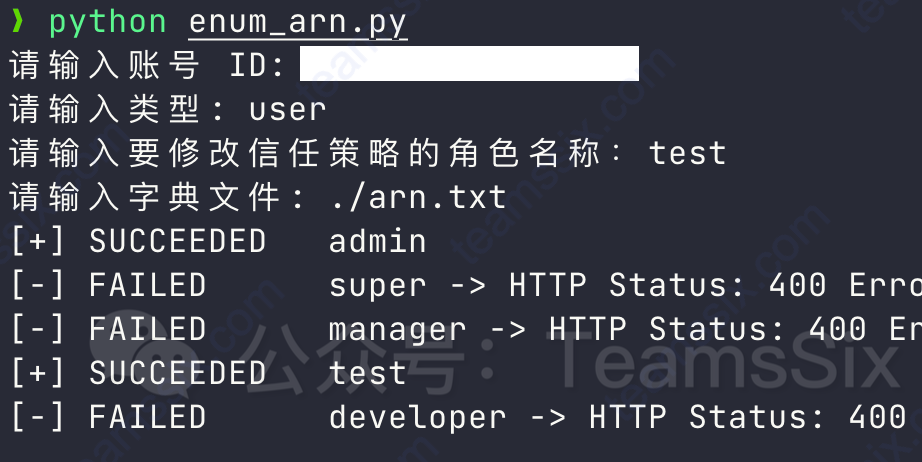 利用信任策略枚举云上用户与角色
利用信任策略枚举云上用户与角色
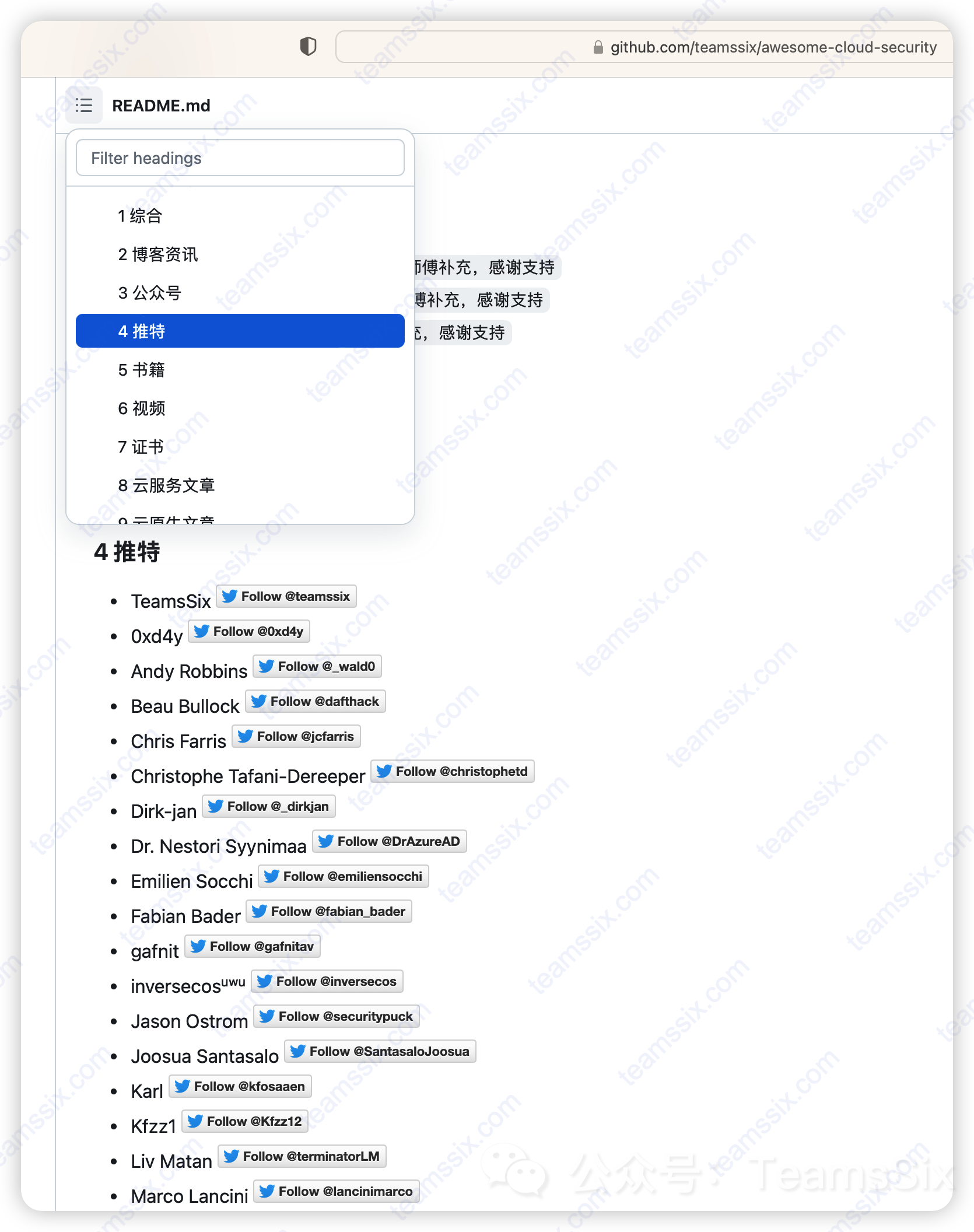 这几个月来 T Wiki 云安全知识库更新了什么
这几个月来 T Wiki 云安全知识库更新了什么
 WIZ IAM 挑战赛 Writeup
WIZ IAM 挑战赛 Writeup
 聊聊我为什么选择云安全
聊聊我为什么选择云安全
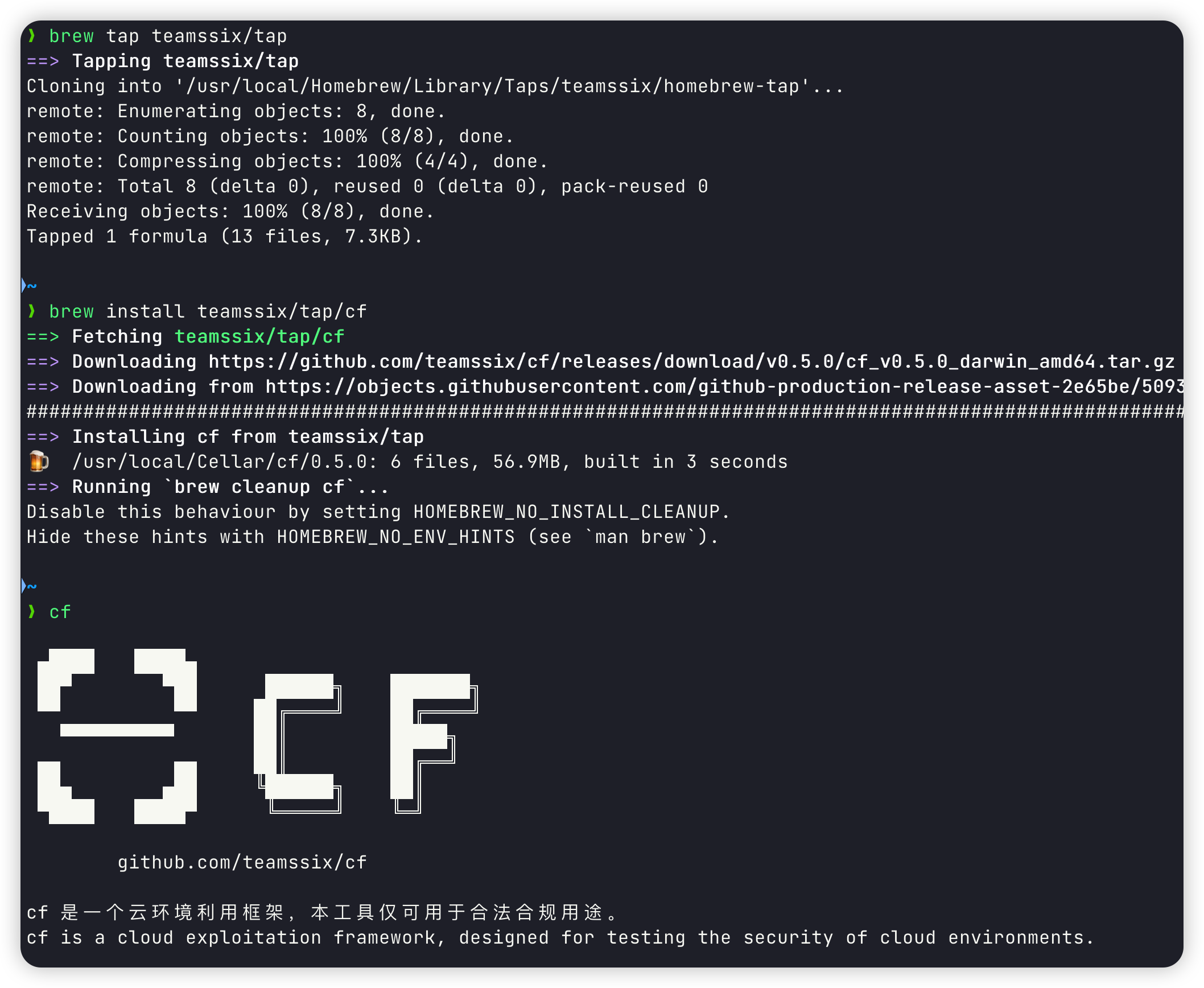 CF 云环境利用框架现已更新至 0.5.0 版本
CF 云环境利用框架现已更新至 0.5.0 版本
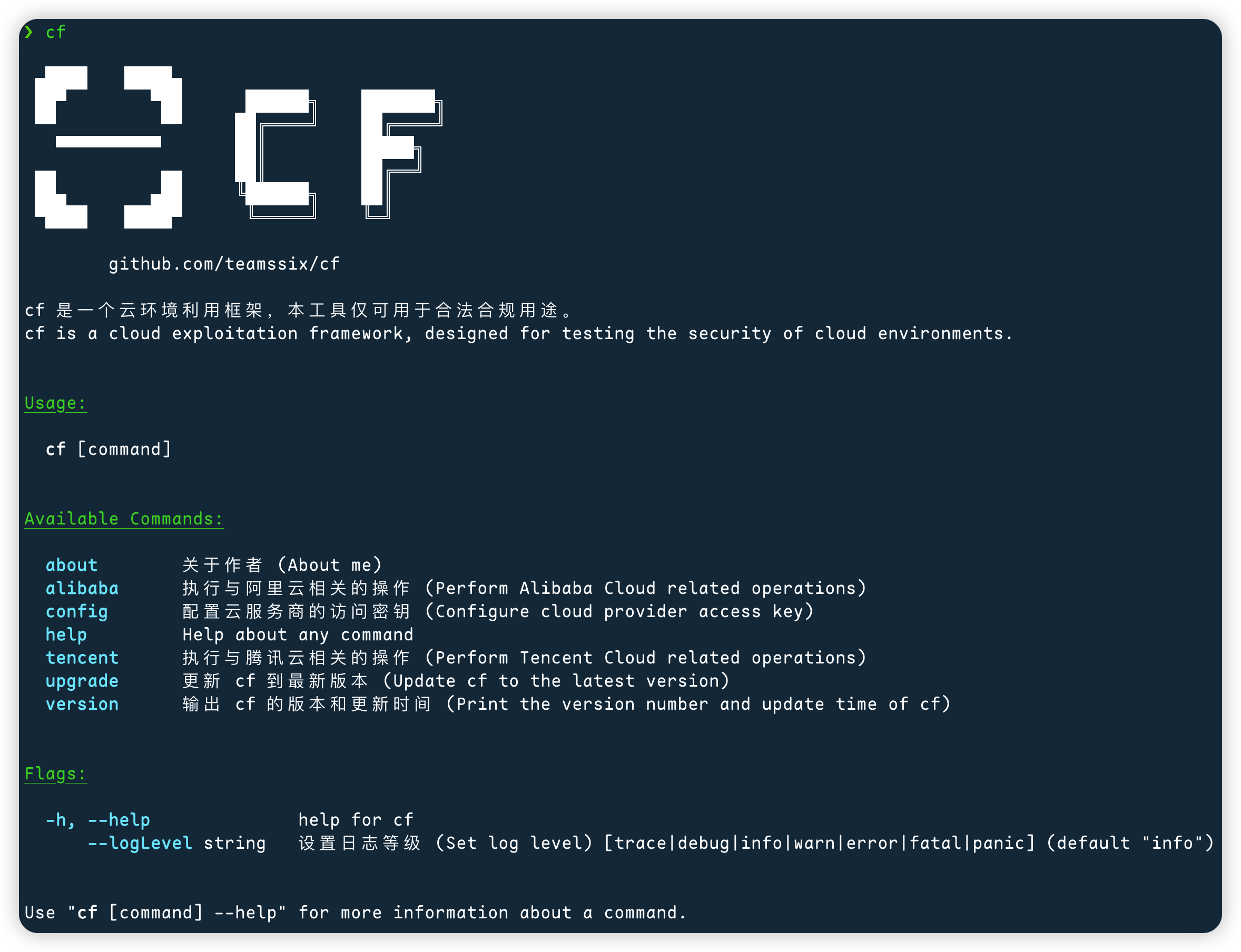 CF 云环境利用框架最佳实践
CF 云环境利用框架最佳实践
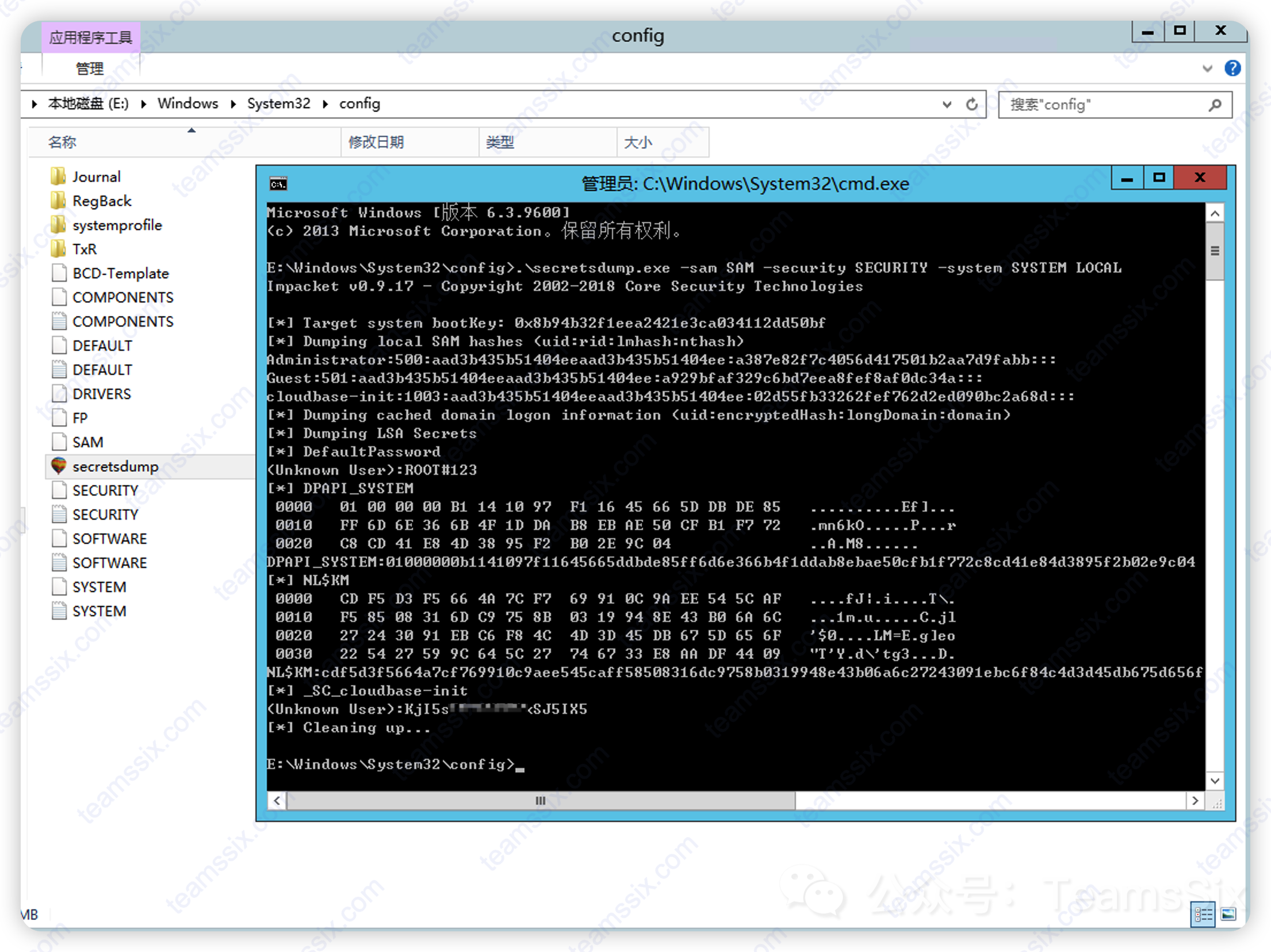 获取无法直接执行命令的 Windows 实例权限
获取无法直接执行命令的 Windows 实例权限
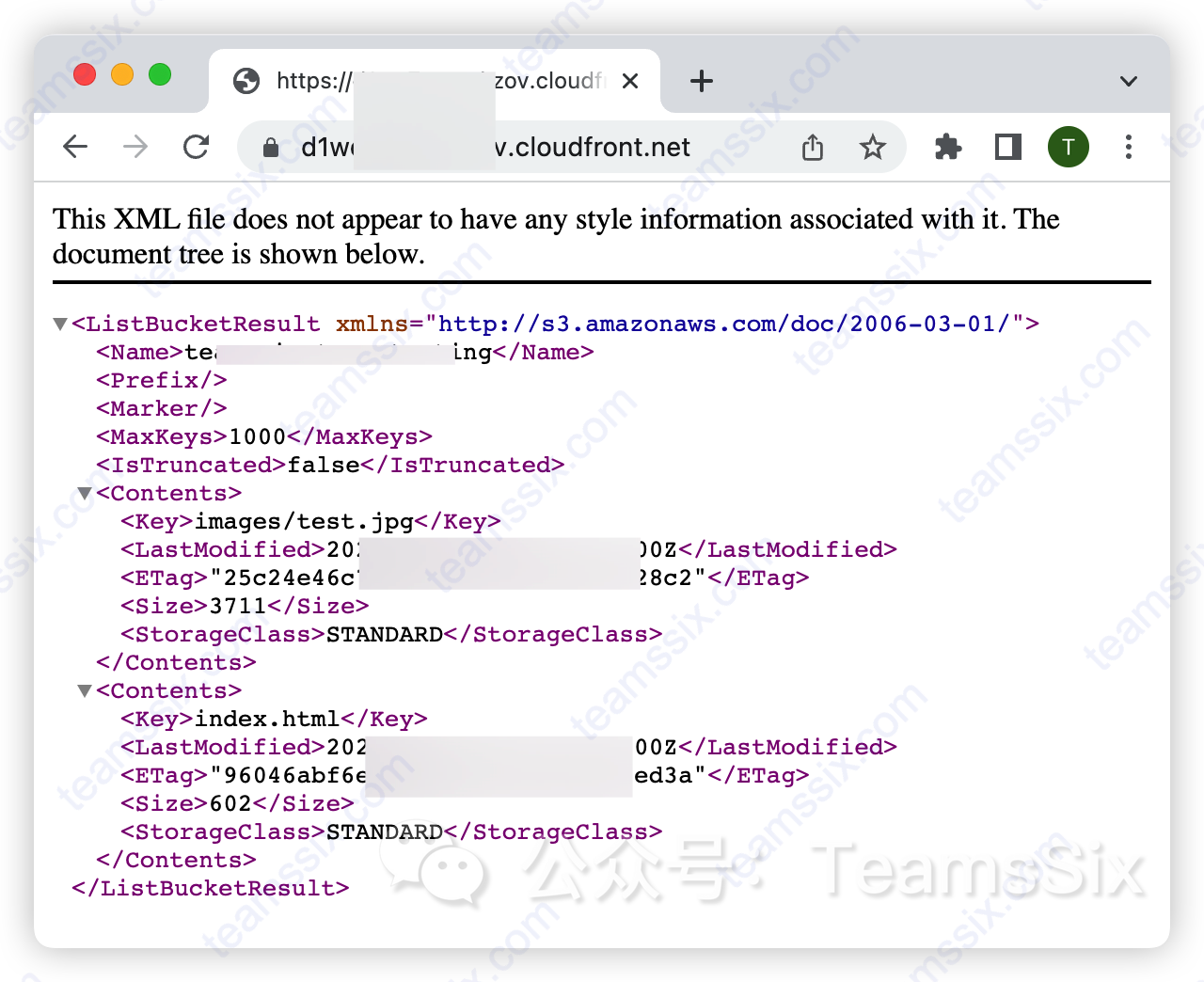 AWS CloudFront 未配置默认根对象的风险简单分析
AWS CloudFront 未配置默认根对象的风险简单分析
 这几个月来 T Wiki 云安全知识库更新了什么
这几个月来 T Wiki 云安全知识库更新了什么
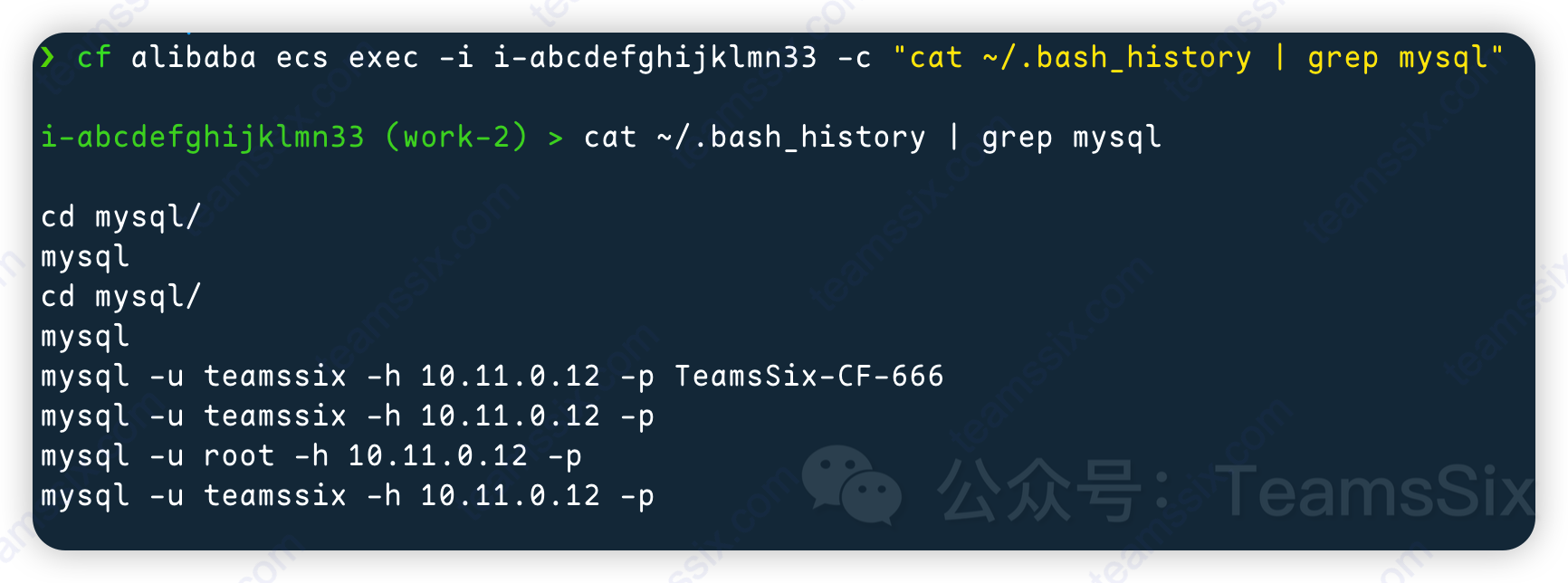 记录一次平平无奇的云上攻防过程
CF 云环境利用框架更新至 v0.4.0 版本
记录一次平平无奇的云上攻防过程
CF 云环境利用框架更新至 v0.4.0 版本
 CF 云环境利用框架工具加入 404 星链计划啦
CF 云环境利用框架工具加入 404 星链计划啦
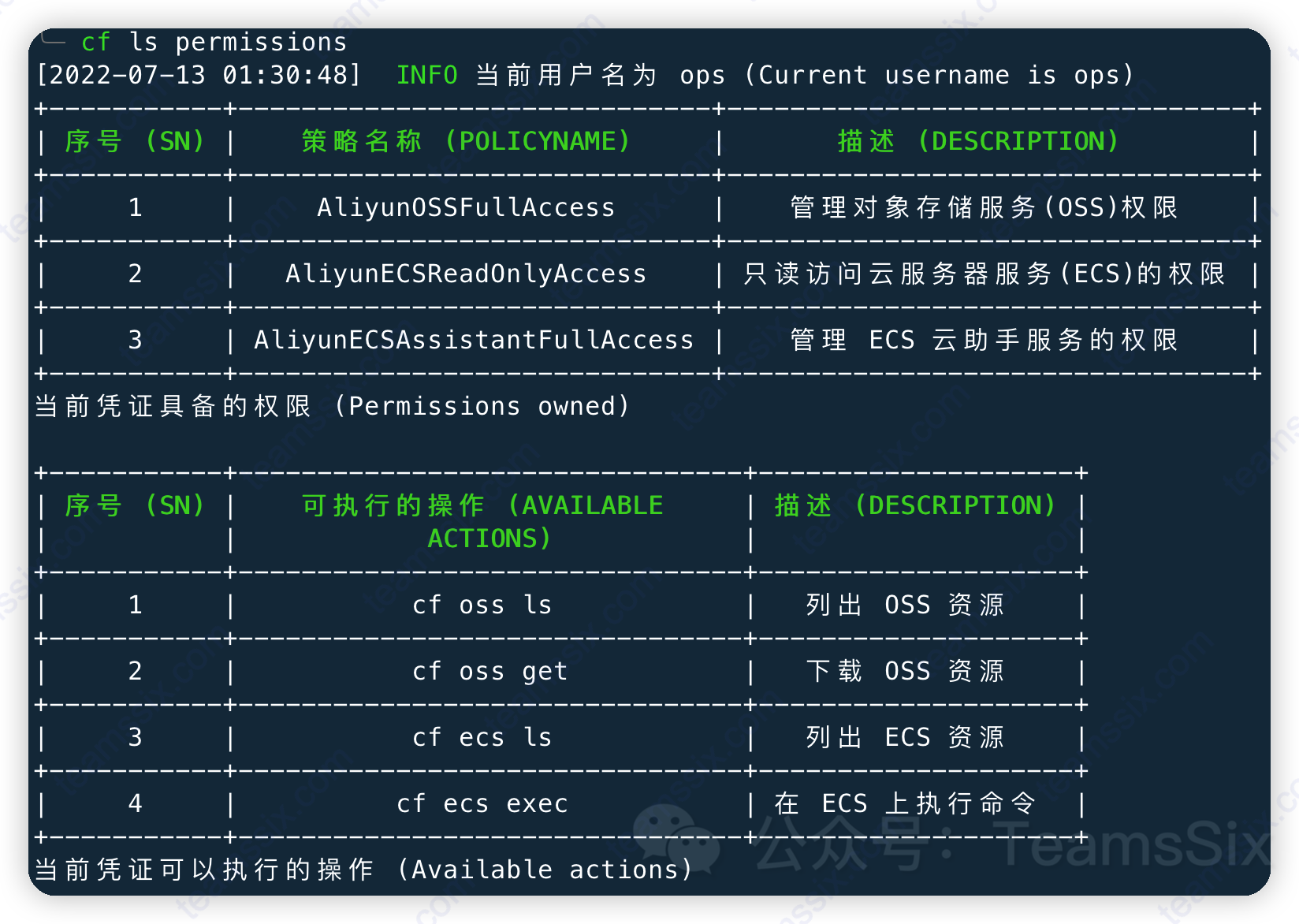 我用 CF 打穿了他的云上内网
我用 CF 打穿了他的云上内网