0x00 简介
下图展示了 Scrapy 的体系结构及其组件概述,在介绍图中的流程前,先来简单了解一下图中每个组件的含义。
Engine
Engine 负责控制系统所有组件之间的数据流,并在某些操作发生时触发事件。
Scheduler
Scheduler 接收来自 Engine 的请求,并对请求进行排队,以便稍后在 Engine 请求时提供这些请求。
Downloader
Downloader 负责获取 web 页面内容并将其提供给 Engine,Engine 再将其提供给 Spiders。
Spiders
Spiders 是由 Scrapy 用户编写的自定义类,用于解析响应并从响应中提取所需要的内容。
Item Pipelines
Item Pipelines 负责处理由 Spiders 提取的数据。典型的任务包括清理、验证和持久性(比如把数据存储在数据库中)。
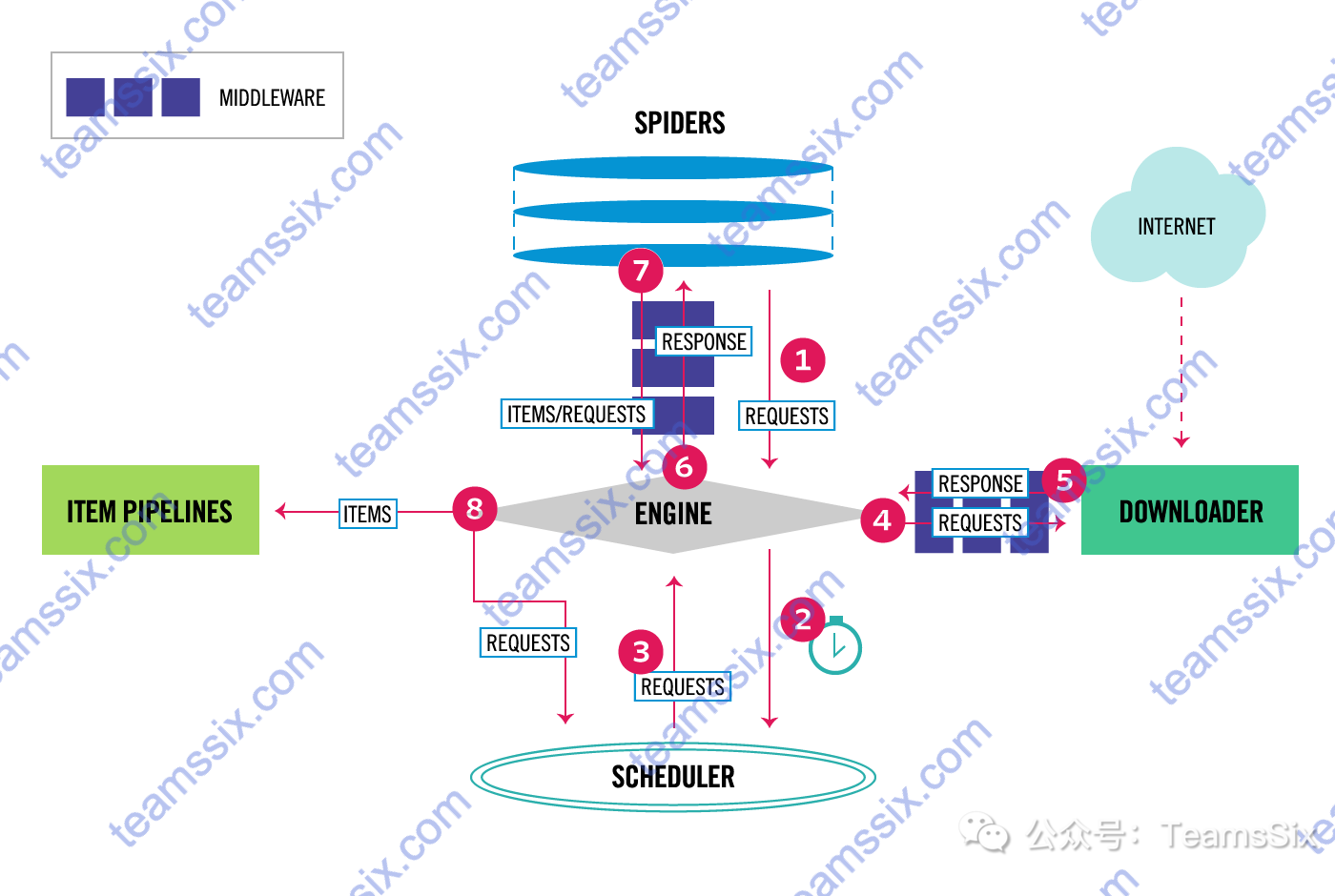
1、Engine 从 Spiders 获取要爬行的初始请求。
2、Engine 在 Scheduler 中调度请求并请求爬行下一个请求。
3、Scheduler 将下一个请求返回给 Engine。
4、Engine 将请求发送给 Downloader,Downloader 对待请求网站进行访问。
5、Downloader 获取到响应后,将响应数据发送到 Engine。
6、Engine 接收来自 Downloader 的响应并将其发送到 Spiders 进行解析处理。
7、Spiders 处理响应后将解析到的数据发送给 Engine。
8、Engine 将处理过的数据发送到 Item Pipelines,然后将处理过的请求发送到 Scheduler,并请求爬行可能的下一个请求,该过程重复(从步骤1开始),直到 Scheduler 不再发出请求为止。
0x01 安装
在安装 Scrapy 之前,建议先安装 Anaconda ,可以省去不少麻烦,Scrapy可以直接 pip 安装,值得注意的是,如果使用 Python2 开发,就需要使用 pip2 安装,使用 Python3 开发就需要使用 pip3 安装,安装命令如下:
pip install scrapy如果安装比较慢,可以指定国内安装源进行安装,下面的命令使用的清华源。
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple使用 -i 指定国内安装源后可以有效的提高下载速度。
更多信息欢迎关注我的个人微信公众号:TeamsSix
参考链接:
https://youtu.be/aDwAmj3VWH4
http://doc.scrapy.org/en/latest/topics/architecture.html