由于这只是学习笔记,因此不会像教程一样详尽,一些我个人已经了解的东西或许不会记在笔记里,因此把笔记当做教程阅读是不合适的。
2020-04-19
 【CS学习笔记】1、如何搭建自己的渗透测试环境
【CS学习笔记】1、如何搭建自己的渗透测试环境
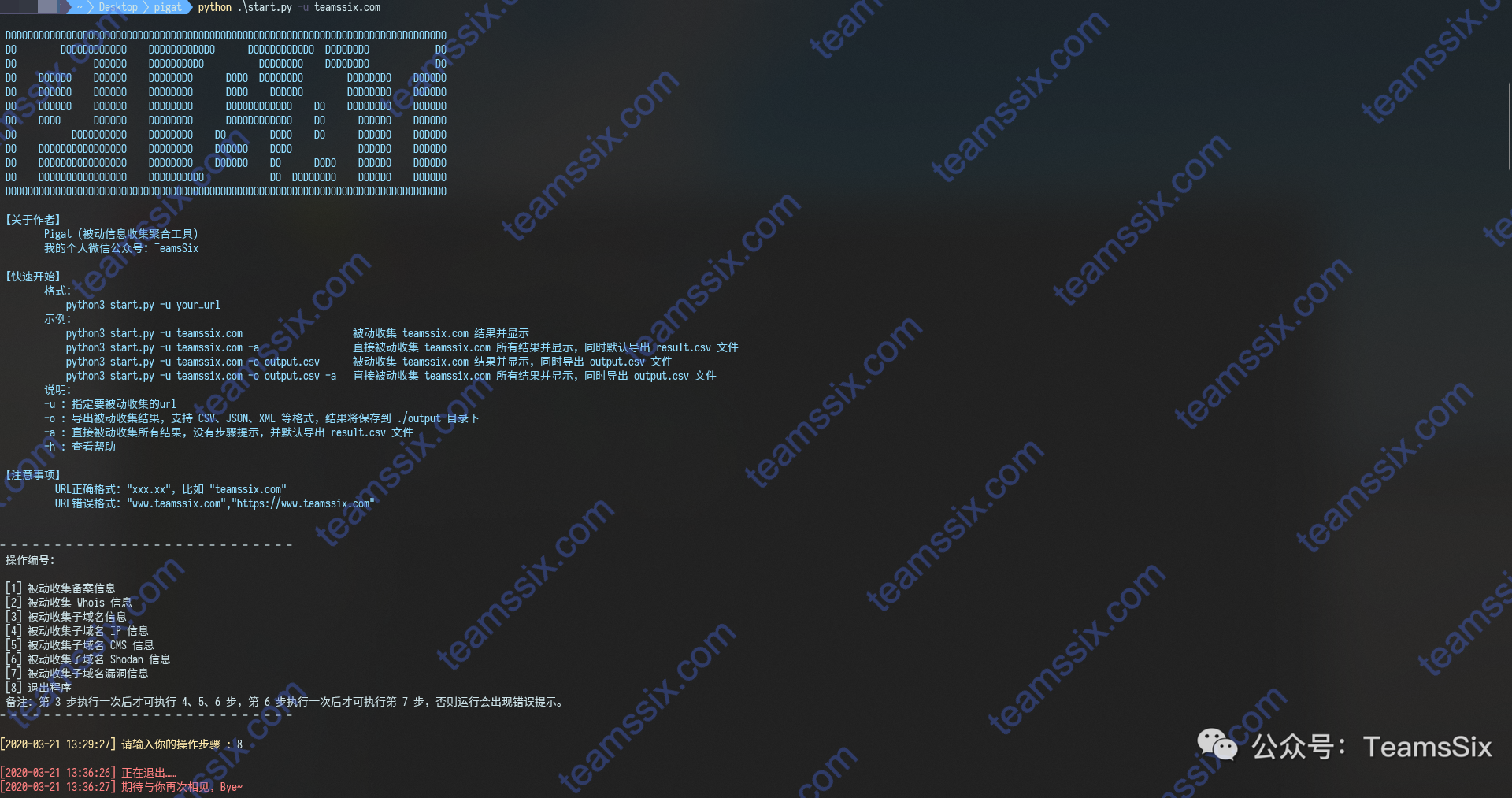 【工具分享】Pigat v2.0正式发布
【工具分享】Pigat v2.0正式发布
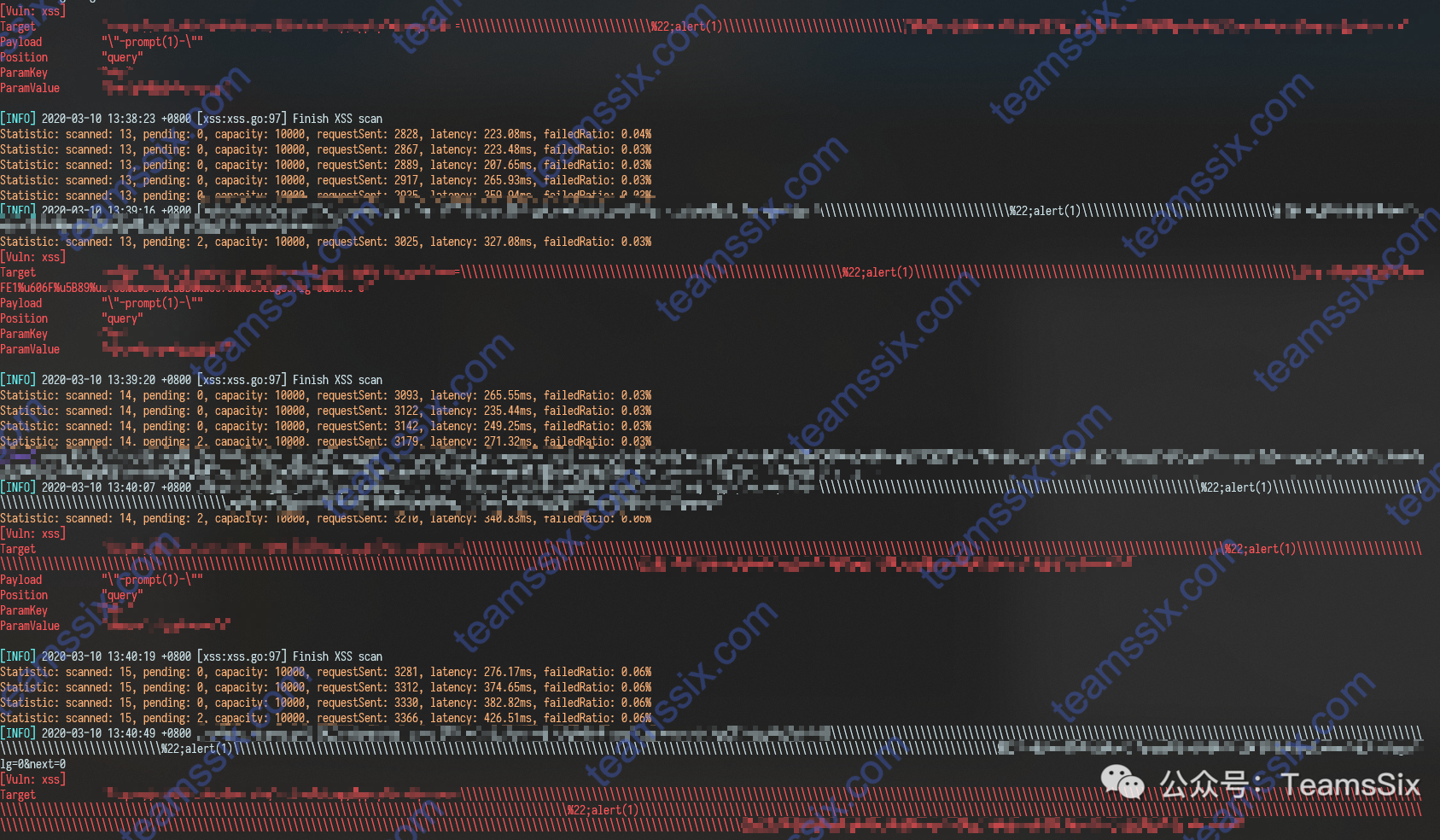 【渗透实例】Fuzz大法好啊
【渗透实例】Fuzz大法好啊
 【Django 学习笔记】5、常用功能
【Django 学习笔记】4、模板
【Django 学习笔记】3、视图
【Django 学习笔记】5、常用功能
【Django 学习笔记】4、模板
【Django 学习笔记】3、视图
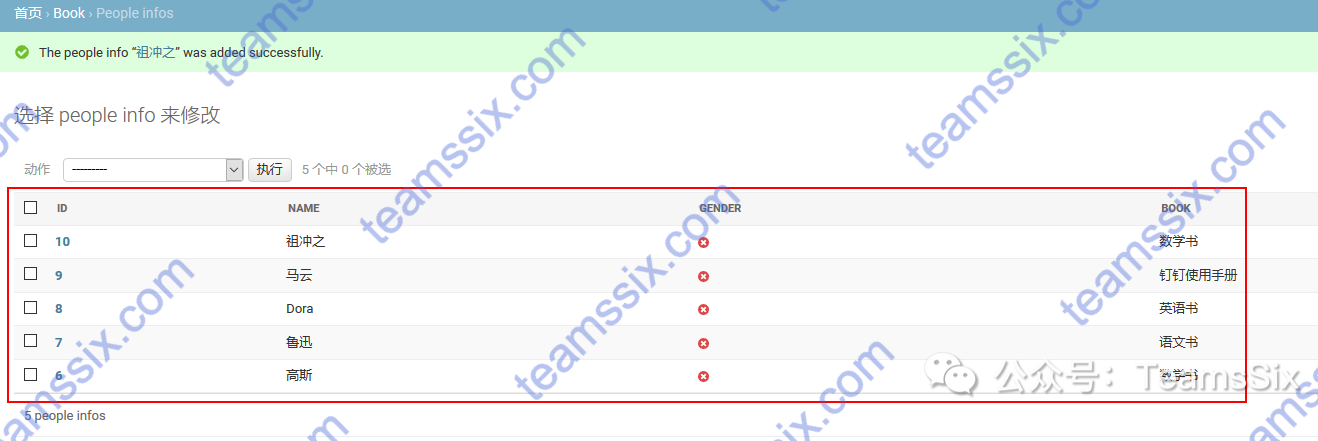 【Django 学习笔记】2、模型
【Django 学习笔记】2、模型
 【Django 学习笔记】1、基础概念和MVT架构
【Django 学习笔记】1、基础概念和MVT架构
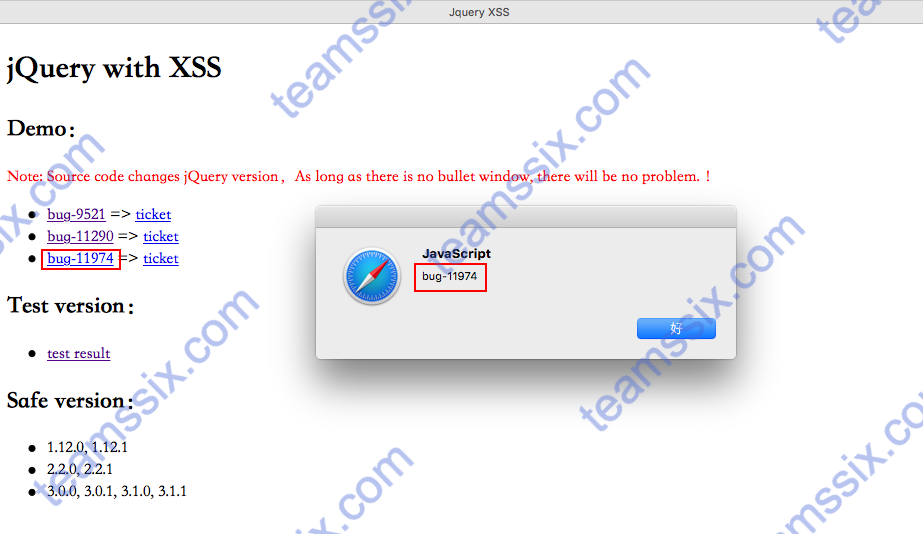 【工具分享】分享一个jQuery多版本XSS漏洞检测工具
【工具分享】分享一个jQuery多版本XSS漏洞检测工具
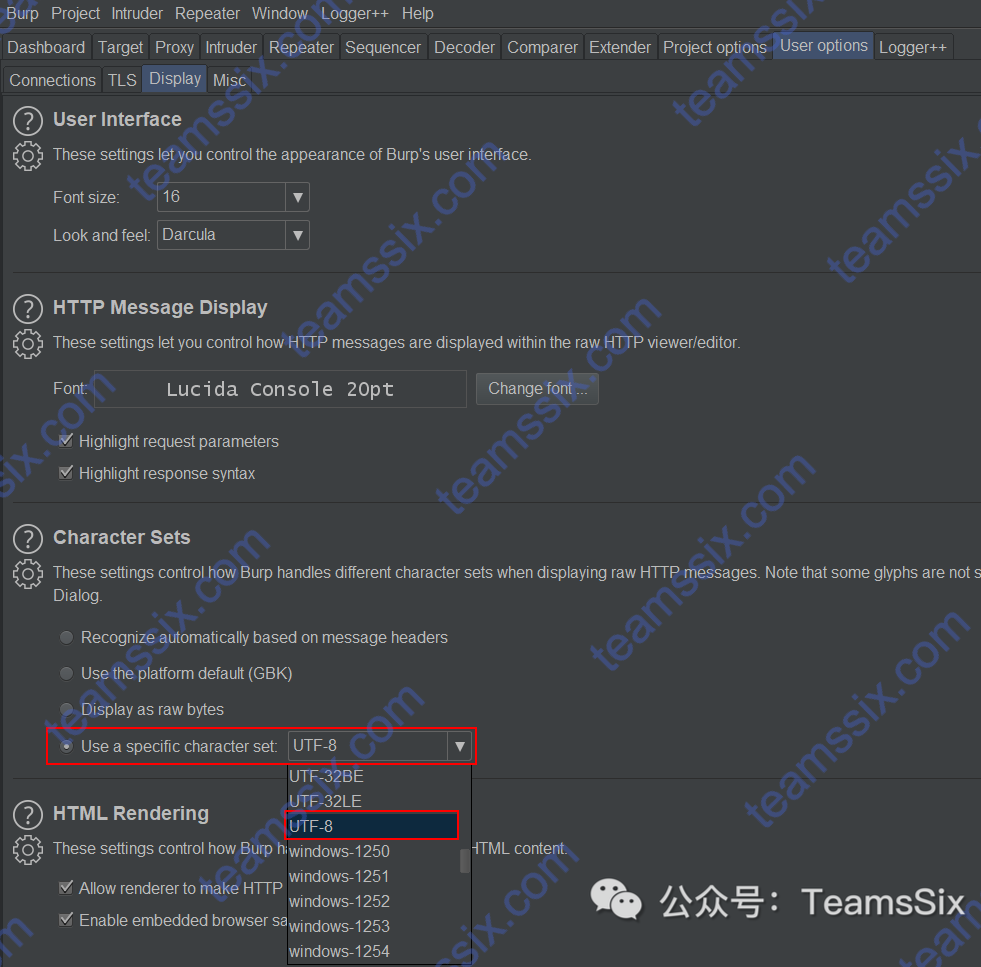 【经验总结】解决 BurpSuite Pro v2020.1 版本中文乱码问题
【经验总结】解决 BurpSuite Pro v2020.1 版本中文乱码问题
 【工具分享】BurpSuite Pro v2020.1 无后门专业破解版
【摘要】漏洞组合拳之XSS+CSRF记录
【经验总结】Python3 Requests 模块请求内容包含中文报错的解决办法
【工具分享】BurpSuite Pro v2020.1 无后门专业破解版
【摘要】漏洞组合拳之XSS+CSRF记录
【经验总结】Python3 Requests 模块请求内容包含中文报错的解决办法
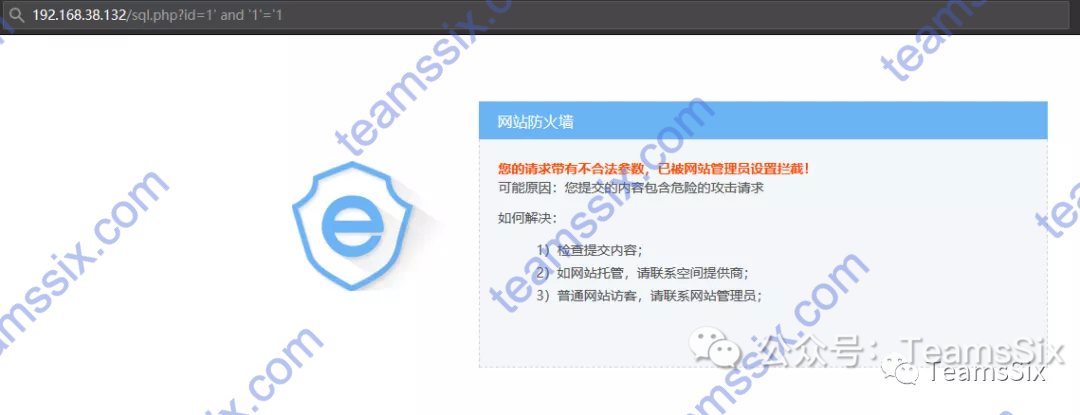 【经验总结】SQL注入Bypass安全狗360主机卫士
【Python Scrapy 爬虫框架】 6、继续爬虫、终止和重启任务
【Python Scrapy 爬虫框架】 5、利用 pipelines 和 settings 将爬取数据存储到 MongoDB
【Python Scrapy 爬虫框架】 4、数据项介绍和导出文件
【Python Scrapy 爬虫框架】 3、利用 Scrapy 爬取博客文章详细信息
【经验总结】SQL注入Bypass安全狗360主机卫士
【Python Scrapy 爬虫框架】 6、继续爬虫、终止和重启任务
【Python Scrapy 爬虫框架】 5、利用 pipelines 和 settings 将爬取数据存储到 MongoDB
【Python Scrapy 爬虫框架】 4、数据项介绍和导出文件
【Python Scrapy 爬虫框架】 3、利用 Scrapy 爬取博客文章详细信息