0x00 下载视频下载脚本
首先来到我的Github主页,找到Douluo-download项目,点开找到下载地址,使用git clone对其进行下载
git clone https://github.com/teamssix/Douluo-download.git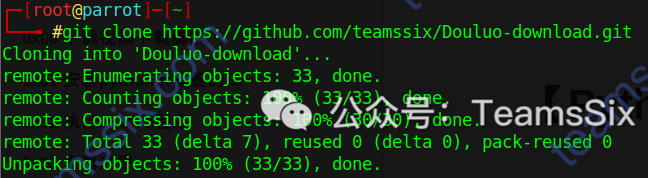
0x01 安装python所需要的库
cd Douluo-download/
pip3 install -r requirements.txt
0x02 执行Python程序
python3 douluo.py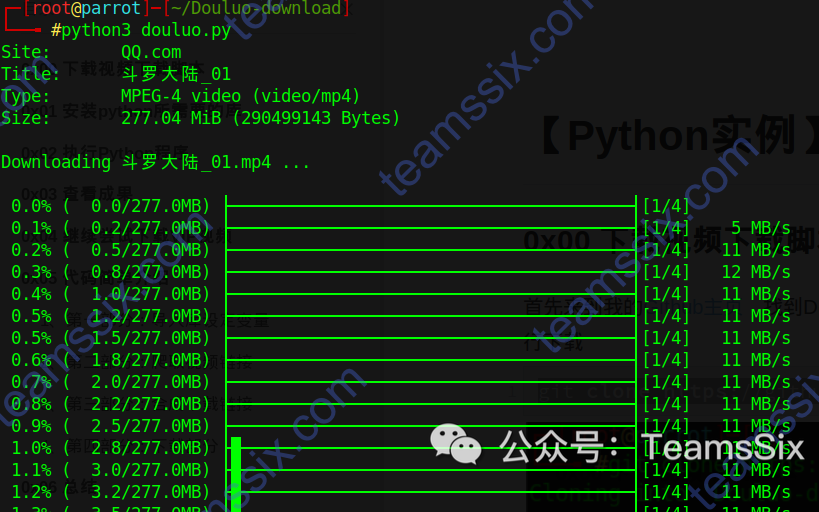
程序在执行的时候会感觉比较慢,其实不是卡了,而是程序正在下载视频,当下载好一个视频才会弹出一条信息。
0x03 查看成果
执行ls命令可以看到刚才下载的视频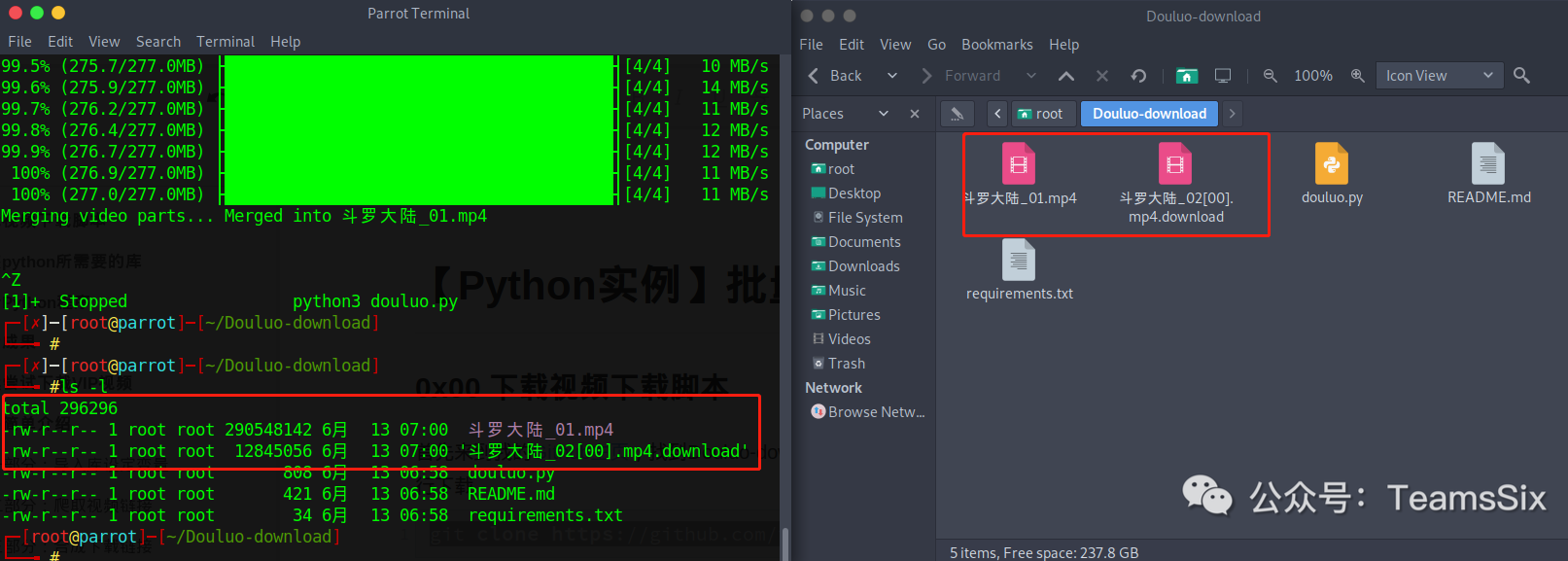
播放看看能不能正常播放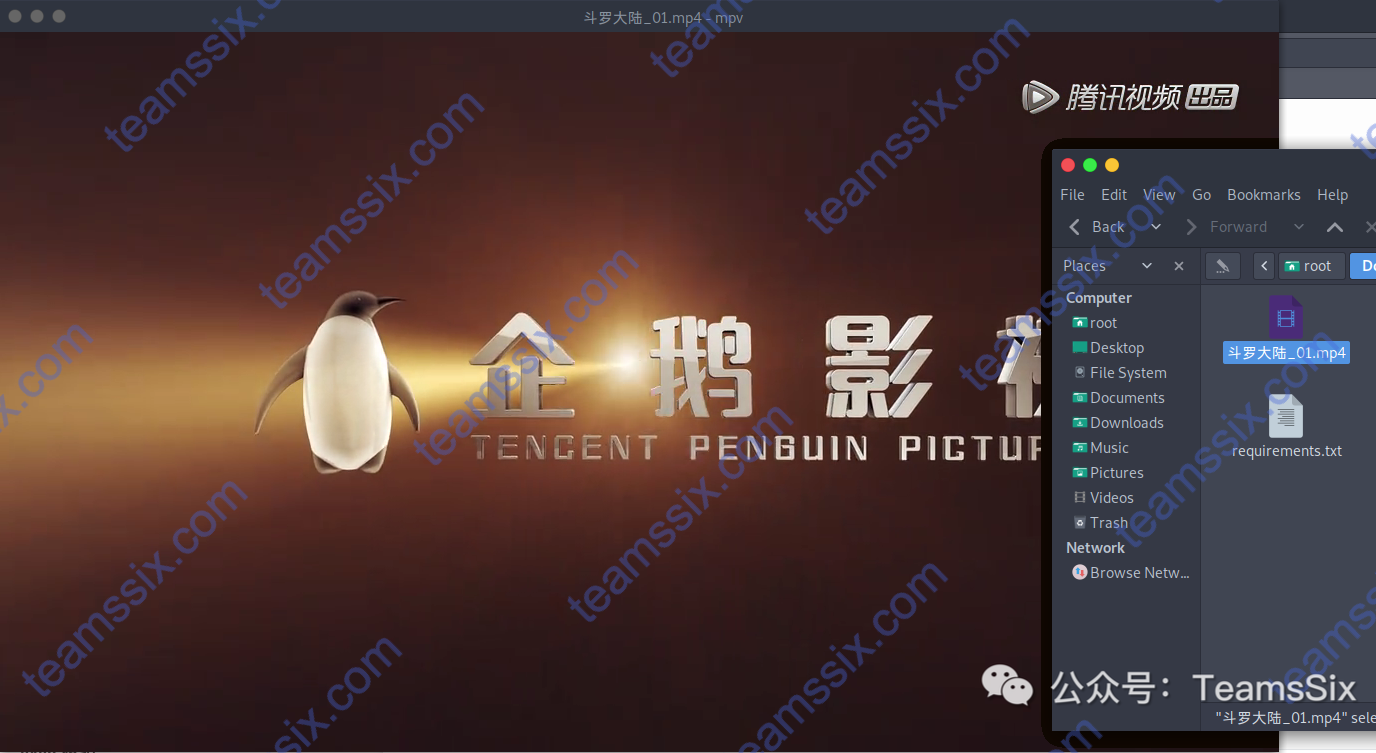
可以看到是可以正常播放的,不过我想试试最新的一集,也就是看看需要会员的视频能不能下载下来,当前最新的一集是55集,那我们下载试试。
0x04 继续尝试下载VIP视频
知道下载那一集后还需要修改一下代码才行,将原来下载视频的代码简单做一下修改就行
执行看看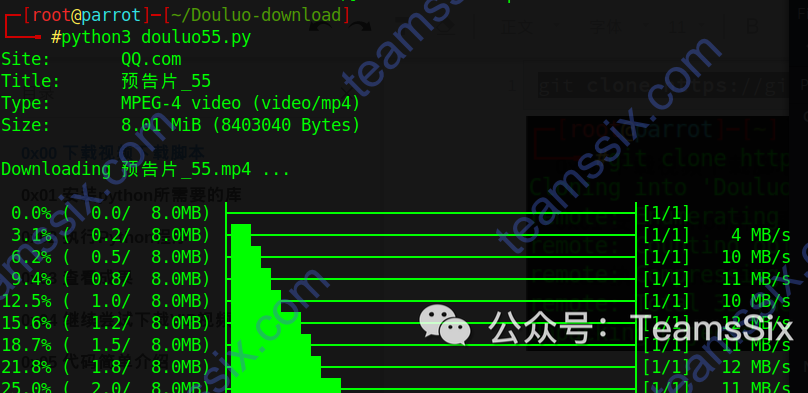
看来不行,只能下载到预告片,接下来就对代码就行简单的介绍吧
0x05 代码简单介绍
1、第一部分:导入库设定变量
#导入库设定变量
import os
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'}
home_url ='https://v.qq.com/x/cover/m441e3rjq9kwpsc/m00253deqqo.html'这部分就是导入一些库和一些设定的变量什么的,比如headers、url什么的,没什么好说的
2、第二部分:爬取每个视频的id
#爬取每个视频的id
douluohome = requests.get(home_url,headers=headers)
douluohome.encoding='utf-8'
douluosoup = BeautifulSoup(douluohome.text,'html.parser')
douluolist = douluosoup.select('.mod_episode')[0].select('a')这里用到了BeautifulSoup4库,先requets获取页面信息,用BeautifulSoup4去对页面html进行解析,最后找到我们想要的东西,这里是清洗出每个视频的ID
3、第三部分:合成下载链接
#合成下载链接
lists = []
for i in range(len(douluolist)):
lists.append('https://v.qq.com'+douluolist[i]['href'])很简单的一个处理,将上一步获取的视频的id加到v.qq.com后面,生成视频的播放链接
4、第四部分:开始下载视频
#开始下载视频
for i in range(len(lists)):
try:
print(os.popen('you-get {}'.format(lists[i])).read()) #视频会下载到当前目录
except:
pass
continue这部分其实也没有什么东西,有了每个视频的播放链接后,直接使用工具就可以下载了,这里使用的是利用os库调用you-get命令进行下载的,最后将you-get命令的显示结果传回终端。
0x06 总结
总的说来,其实Python主要就是起到爬虫作用,爬取每个视频的播放链接,最后使用you-get对视频进行下载,没有什么太大的难度,所以权当练练手了。
下面为视频演示:
如果视频不能全屏播放,请点击源链接观看。
![]()