0x00 前言
这是一款对URL进行批量识别存活、常见端口、标题、Banner等信息的工具,虽然之前也写过类似的工具,但是要不速度太慢就是识别出来的效果不够理想。
后来发现httpx能够很好的完成这样的一个需求,但是 httpx 的命令是在有些长,每次使用都要输入很长的一段命令,而且导出的数据不够直观。
所以本工具在httpx的基础上简化了输入的命令长度同时将结果进行excel表格的导出,便于对收集到的信息进行整理。
这个工具自己也使用了差不多有1个月的时间,发现平时在做资产收集的时候,效率提升的还是很明显的,因此便打算把这个工具分享出来供大家使用,如果感觉还不错欢迎给个star。
本工具项目地址:https://github.com/teamssix/url_batch_discovery
0x01 安装
1、安装 httpx
在使用本工具前需要先安装httpx工具,httpx项目地址:https://github.com/projectdiscovery/httpx
在httpx的releases页面下载适合自己系统的安装包,然后添加到系统路径即可,最后在命令行中能成功执行httpx --version即表示安装成功了。
2、安装本工具
git clone https://github.com/teamssix/url_batch_discovery.git
cd url_batch_discovery
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
python3 url_batch_discovery.py -h0x02 使用
- 命令说明
-h, --help show this help message and exit
-l LIST 指定URL列表文件
-m MATCH 指定要匹配的关键字,返回结果中将只包含存在该关键字的内容
-o OUTPUT 导出的文件路径,默认保存在./output/文件夹内,导出文件格式为xlsx,格式:/path1/path2/
-p PORT 指定要检测的端口,默认只对80和443端口进行检测,格式:80,443,8000-8010
-t THREADS 指定线程大小,默认50个线程
-u URL 指定单个URL- 对 url.txt 里的url进行批量识别
python3 url_batch_discovery.py -l url.txt- 对 url.ttx 进行80,443,8080-8090的端口识别
python3 url_batch_discovery.py -l url.txt -p 80,443,8080-8090- 对 url.ttx 进行批量识别,且只返回网页中存在“JBoos”字符的URL
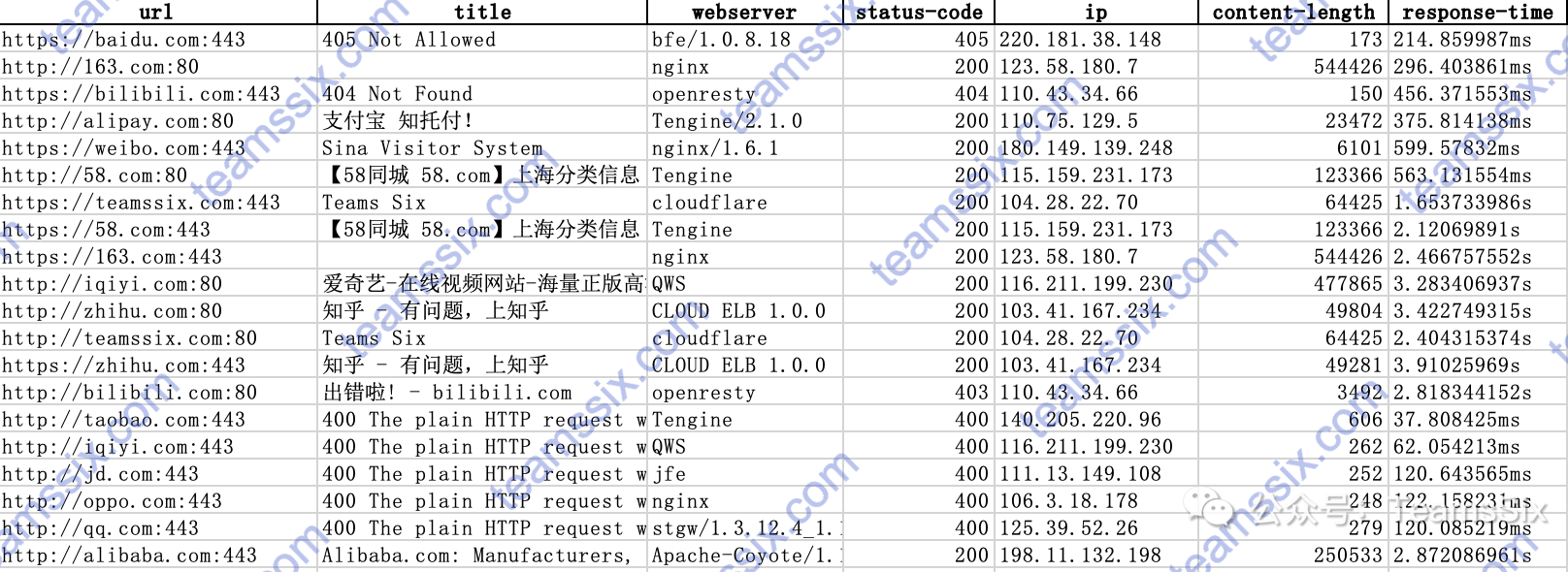
python3 url_batch_discovery.py -l url.txt -m "JBoss"0x03 工具截图
- 帮助信息

- 导出表格
0x04 注意事项
- 本工具使用 Python3 开发,因此需要 Python3 环境支持
- 本工具核心功能来自 httpx
- 本工具的运行速度取决于你设置的线程大小以及端口数量的多少
- 如果使用过程中碰到 bug,欢迎提 issue,如果帮助到你,欢迎赏个 star
![]()