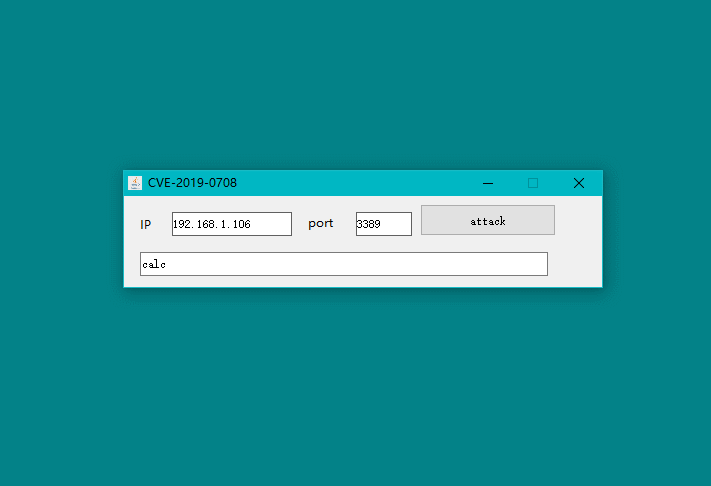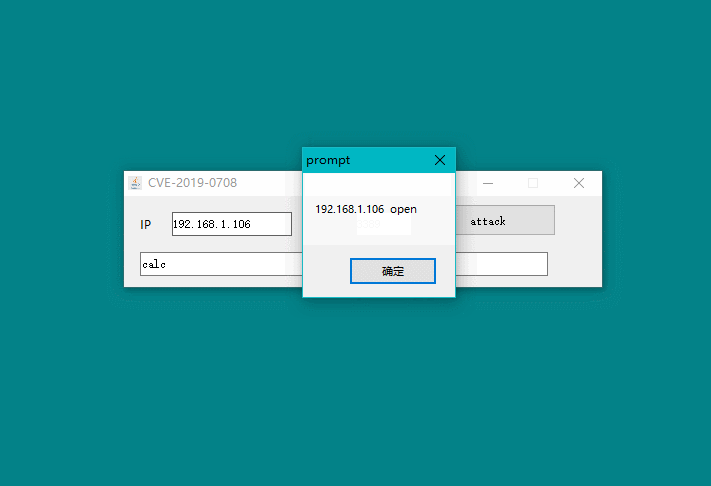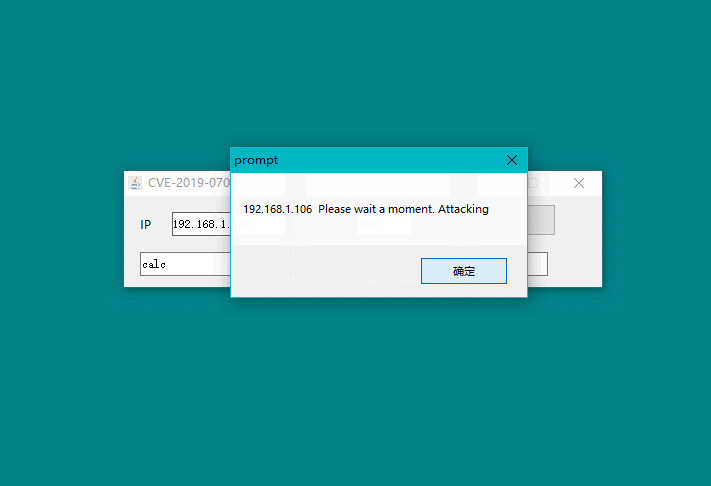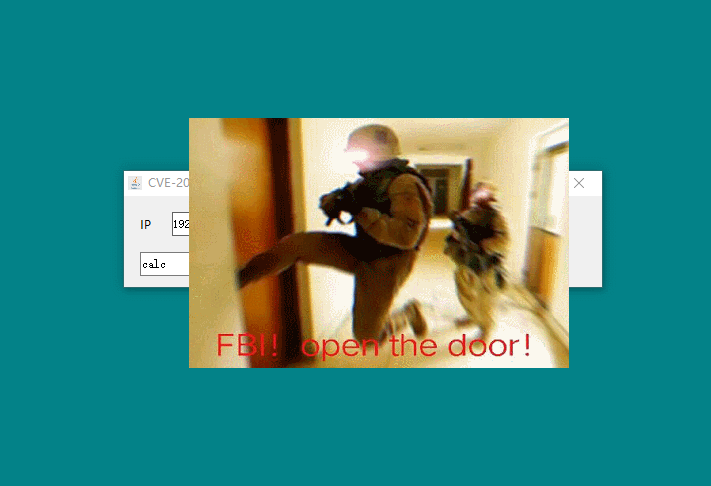
话不多说,先让我们看看最终效果图:

那么如何使用Python来获取这些信息呢?
一、需求与思路
1、需求
首先要知道最近正在上映的电影的名称、评分、评论数等等,这些都可以在豆瓣上找得到,因此本次数据挖掘对象就确定为豆瓣电影官网。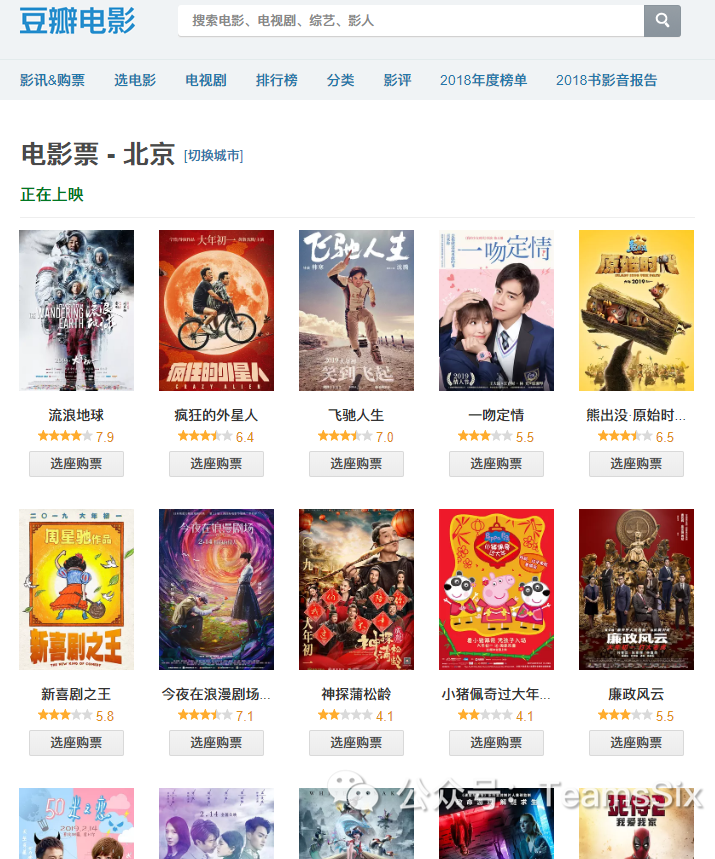
2、思路
a、调用requests模块向豆瓣电影官网发出请求
b、调用BeautifulSoup模块从返回的html中提取数据
c、调用pandas模块将提取的数据转为表格样式
二、开工
1、发出请求
设置好headers,url,调用requests模块向目标网站发出请求,最后结果存储在res中
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url = 'https://movie.douban.com/cinema/nowplaying/beijing/'
res = requests.get(url,headers = headers)2、数据传入
将html文本传入BeautifulSoup中,指定解析器为html.parser,并将解析内容传入soup
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,'html.parser')三、数据提取
在介绍数据提取之前需要先介绍一个插件:infolite,这款插件可以直接查看到控件路径,而不需要到复杂的开发人员工具中就行查看。
1、电影名
打开电影详情页面,找到电影名控件路径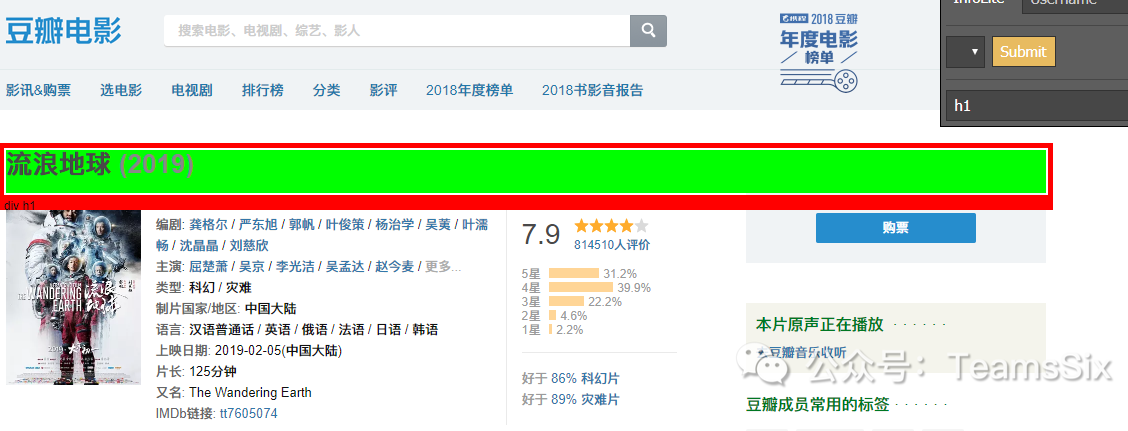

最终修改为以下结果得到电影名称
insoup.select('h1')[0].text.split()[0]
2、豆瓣评分
根据同样原理可得到该电影的评分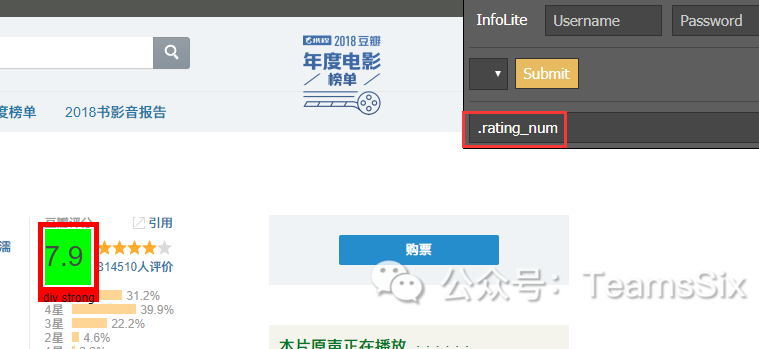
insoup.select('.rating_num')[0].text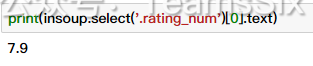
3、评论数量
依旧是一样的思路,先利用InfoLite找到控件路径,再利用bs4模块提取对应内容。
insoup.select('.mod-hd a')[1].text.split()[1]
4、简介
对于简介因为里面有很多空格换行等,所以这里使用了正则替换空格。
re.sub('\s','',insoup.select('.related-info span')[0].text)
这里写个函数,为实现传入一个URL,返回该URL中信息的功能,最终四项都将传入result字典中,所以接下来要做的就是如何获取URL。
def pages(url):
result = {}
inres = requests.get(url,headers = headers)
insoup = BeautifulSoup(inres.text,'html.parser')
result['电影名'] = insoup.select('h1')[0].text.split()[0]
result['豆瓣评分'] = insoup.select('.rating_num')[0].text
result['评论数量'] = insoup.select('.mod-hd a')[1].text.split()[1]
result['简介'] = re.sub('\s','',insoup.select('.related-info span')[0].text)
return result四、提取URL
因为我们要找的电影是正在上映的电影,因此从正在上映的电影列表中提取URL即可。
url = 'https://movie.douban.com/cinema/nowplaying/beijing/'
res = requests.get(url,headers = headers)
soup = BeautifulSoup(res.text,'html.parser')在soup中含有这些链接,soup.select()是列表类型,有的列表项含有URL,有的不含有,并且在调试过程中发现有的含有链接的却没有评分信息。
因此在以下语句中URL利用select存到urls中,利用判断语句来筛选掉一些没有评分的电影。
pools = []
for links in soup.select('ul'):
urls = links.select('a')[0]['href']
if len(links.select('.subject-rate')) > 0 :
pools.append(pages(urls))最终,每个URL的信息都被添加到pools数组中,但是这个时候直接输出pools会很乱,因此接下来要做的就是生成表格。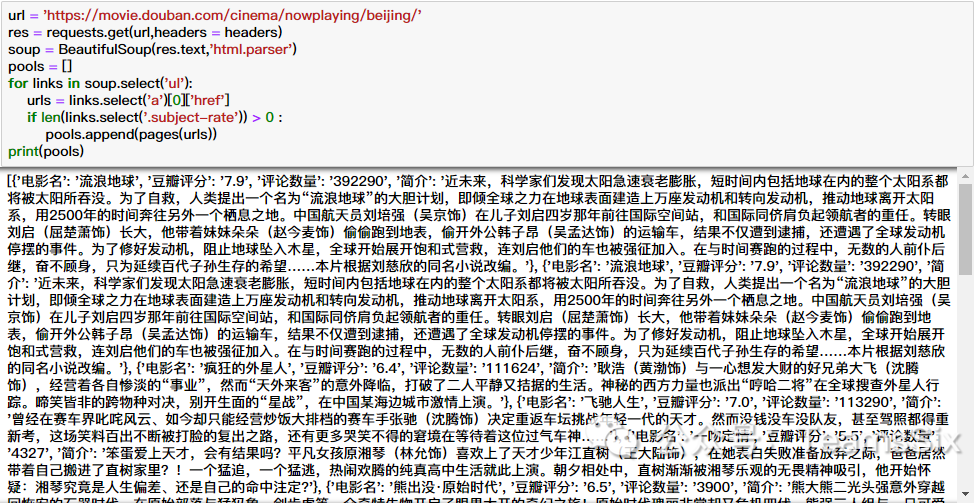
五、表格生成
生成表格的方法也非常简单
import pandas
df = pandas.DataFrame(pools)
df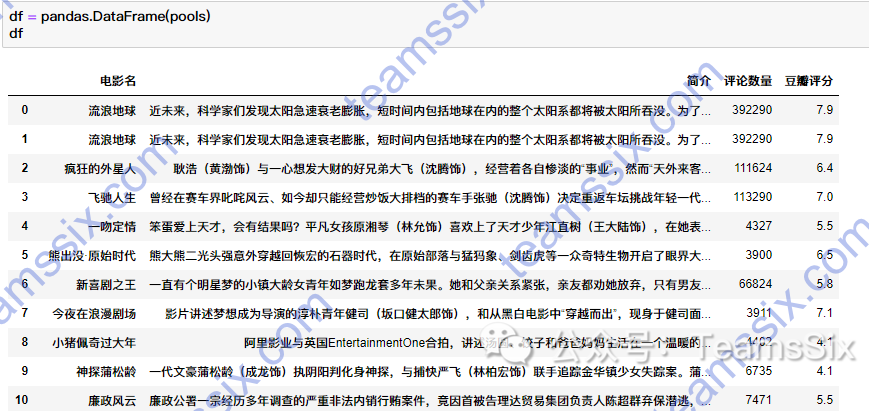
不过这样不够明显,因此我们可以将简介放到后面,再排序一下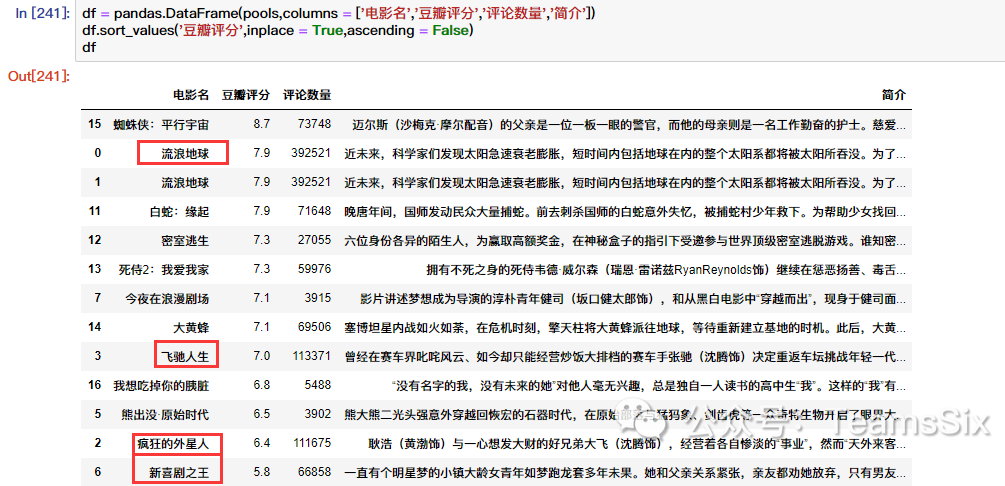
六、总结
上面一张图可以明显看到今天的四个贺岁电影中,《流浪星球》不管是豆瓣评分还是评论的数量都是第一个,倒也是实至名归。
在整个过程中,碰到了很多问题,其中不乏有还未解决的问题,比如在提取电影标签的时候,因为正则使用的不熟而一直没有被很好的提取出来。
在做这个数据挖掘之前,还做了新浪新闻的信息抓取,这个电影信息的数据挖掘也相当于是练练手,后面还有的导出文档、导出到数据库的功能就没有做演示了,也是几行代码的事情。
用了一段时间Python后,真的不得不感叹到Python的强大之处,下面就把以上项目的全部代码展示出来吧,另外我还是个新手,代码写得十分笨拙,大佬还请绕步。
import re
import pandas
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url = 'https://movie.douban.com/cinema/nowplaying/beijing/'
res = requests.get(url,headers = headers)
soup = BeautifulSoup(res.text,'html.parser')
pools = []
for links in soup.select('ul'):
urls = links.select('a')[0]['href']
if len(links.select('.subject-rate')) > 0 :
pools.append(pages(urls))
df = pandas.DataFrame(pools,columns = ['电影名','豆瓣评分','评论数量','简介'])
df.sort_values('豆瓣评分',inplace = True,ascending = False)
df
def pages(url):
result = {}
inres = requests.get(url,headers = headers)
insoup = BeautifulSoup(inres.text,'html.parser')
result['电影名'] = insoup.select('h1')[0].text.split()[0]
result['豆瓣评分'] = insoup.select('.rating_num')[0].text
result['评论数量'] = insoup.select('.mod-hd a')[1].text.split()[1]
result['简介'] = re.sub('\s','',insoup.select('.related-info span')[0].text)
return result![]()